Description
Back to topIn recent years, many novel methods and directions have emerged in reinforcement learning and control. A particularly exciting development is the use of online optimization and statistical learning techniques in control theory. This has led to novel methods and guarantees in various contexts, including in stochastic and adversarial environments, system identification, iterative planning and sequence prediction. Other topics we will cover include new connections between control and both model-free and model-based reinforcement learning, as well as learning dynamical systems. We aim to bring together researchers to facilitate progress along these lines of investigation, and discuss important future directions in reinforcement learning, control, learning dynamical systems and applications to sequence prediction.
Poster Session and Lightning Talks
This workshop will include a poster session and lightning talks for early career researchers (including graduate students). In order to propose a poster or a lightning talk, you must first register for the workshop, and then submit a proposal using the form that will become available on this page after you register. You can request to do one, or both. The registration form should not be used to propose a poster or a lightning talk.
The deadline for proposing is Sunday, March 15, 2026. If your proposal is accepted, you should plan to attend the event in-person.
In-Person Registration
Seats are limited at the venue, which means that in-person registration may be capped prior to the workshop start date. If capacity is reached, a waitlist will be imposed, which the registration form will reflect. Early registration is strongly encouraged.
All in-person registrants must wait to receive an invitation to attend in-person from IMSI before traveling, which generally begin to be sent out 4-6 weeks in advance.
All registrants (online and in-person) will receive zoom links and are welcome to attend online.
Organizers
Back to topSpeakers
Back to topSchedule
Speaker: Elad Hazan (Princeton University)
Speaker: Dylan Foster (Microsoft Research)
Speaker: Nathan Srebro (University of Chicago and Toyota Technological Institute at Chicago)
Speaker: Drew Bagnell (Carnegie Mellon University and Aurora)
Speaker: Nadav Cohen (Tel Aviv University)
Speaker: Annie Marsden (Google Deepmind)
Speaker: Florian Dorfler (University of Pennsylvania)
Speaker: Necmiye Ozay (University of Michigan)
Speaker: Daniel Russo (Columbia University)
Speaker: Sarah Dean (Cornell University)
Speaker: Na Li (Harvard)
Speaker: Dale Schuurmans (University of Alberta)
Speaker: Stephen Tu (University of Southern California (USC))
Speaker: Noah Golowich (Microsoft Research NYC)
Speaker: Zak Mhammedi (Google Reasearch)
Speaker: Gautam Goel (University of California, Berkeley (UC Berkeley)
Speaker: Max Raginsky (University of Illinois at Urbana-Champaign)
Speaker: Alex Olshvesky (Boston University)
Poster Session
Back to topPosters submitted in advance can be viewed on this page.
Videos

Provably Efficient Learning in Nonlinear Dynamical Systems
Elad Hazan
May 11, 2026
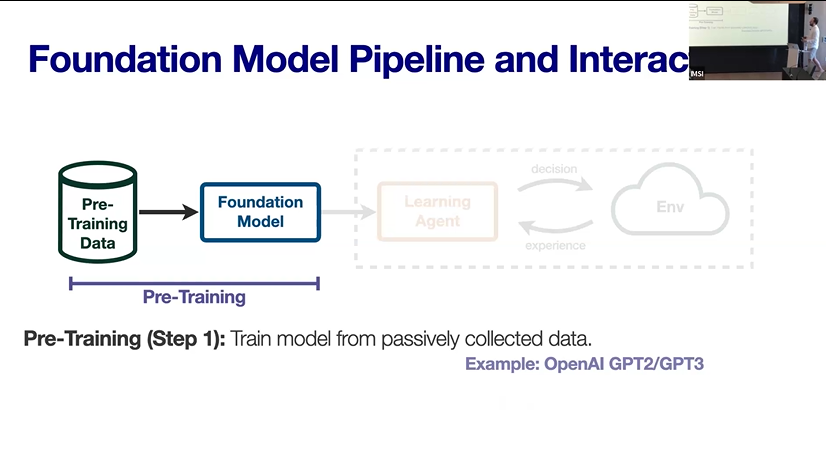
Understanding the foundation model pipeline through coverage
Dylan Foster
May 11, 2026

Learning to Answer from Correct Demonstrations
Nathan Srebro
May 11, 2026

Return of the Reward Function
Drew Bagnell
May 11, 2026

Lightning Talks
Lightning Talks
May 11, 2026

Generalization in AI Agents: Lessons from Linear-Quadratic Control
Nadav Cohen
May 12, 2026

The Power of Universal Sequence Preconditioning
Annie Marsden
May 12, 2026

Learning Pipelines for Adaptive Control
Florian Dorfler
May 12, 2026

Some fundamental limitations of learning for dynamics and control
Necmiye Ozay
May 12, 2026

Success Conditioning as Policy Improvement: The Optimization Problem Solved by Imitating Success
Daniel Russo
May 12, 2026

Learning and control in the presence of observer effects
Sarah Dean
May 13, 2026

From Generative Models to Control: Representation-based Reinforcement Learning in Physical Systems
Na Li
May 13, 2026

Large Language Models and Computation
Dale Schuurmans
May 13, 2026

Latent Representations for Control Design with Provable Stability and Safety Guarantees
Stephen Tu
May 13, 2026

Sequences of Logits and The Low Rank Structure of Language Models
Noah Golowich
May 14, 2026

Decoupling Exploration and Policy Optimization: Uncertainty Guided Tree Search for Hard Exploration
Zak Mhammedi
May 14, 2026

Self-Attention for Online Decision-Making and Control
Gautam Goel
May 14, 2026

Controlled dynamical systems on the space of probability measures
Max Raginsky
May 14, 2026

Can Gradient Descent Beat Ricatti?
Alex Olshvesky
May 14, 2026